
В данной статья я хочу сделать обзор того чем сегодня является serverless, что значит сделать serverless решение, какие инструменты для этого есть, какие есть ограничения и когда стоит задуматься о serverless. Даннная статья не полный и всеобъемлющий гайд по serverless, я постараюсь описать то, что знаю, слышал, с чем имел дело. Надеюсь, что статья будет полезна на начальном этаме знакомства с serverless и поможет быстрее съориентироваться и пойти в правильном напривлении.
Serverless как подход для построения решений
Часто под serverless подразумевают только вычисления и функции типа aws lambda. Но serverless намного шире, это не только вычисления но и хранение данных, интеграции, бизнес процессы.
Определение
Посмотрим для начала на определение от AWS:
Бессерверная архитектура – это способ создания и запуска приложений и сервисов без необходимости управления инфраструктурой. Приложение по‑прежнему будет работать на серверах, но управление этими серверами AWS полностью берет на себя. Вам больше не придется заниматься выделением ресурсов, масш�табированием и обслуживанием серверов для запуска приложений, баз данных и систем хранения данных.
from: https://aws.amazon.com/ru/lambda/serverless-architectures-learn-more/
Тут главная мысль, что инфраструктурой владеет облачный провайдер. Это определенение описывает только одну особенность serverless и поэтому оно не точное.
Вот что пишут в Yandex Cloud о serverless:
Теперь разработчики не задумываются об эксплуатации инфраструктуры и оплачивают только те ресурсы, которые используются для работы приложения.
from: Всё, что вы хотели знать о бессерверных технологиях, но боялись спросить
Тут учтено и то, что мы не платим за ресурсы когда не используем их. Важная оговорка тут в том, что контроль за тем платим мы или нет возложена на провайдера услуг. Это важнр так как и с виртуальными машинами мы можем создавать VM когда она нужна и удалять когда не нужно. Но это дополнительный процесс который мы должны поддерживать и это не serverless.
Довольно точно serverless определяет Yandex Cloud так:
Serverless - это:
- LowCode
- LowOps
- Pay as you go
from: - Yandex Scale 2024. Serverless
где
- LowCode - это не код перенесенный в квадратики, а с LowCode разработчик должен писать меньше кода так как весь бойлерплейт реализован поставщиком сервиса. Например CloudFunction & AWS Lambda берут на себя прием, парсинг запроса, возврат результата и преобразование запроса и ответа.
- LowOps - заботу о инфраструктуре берет на себя провайдер облачных услуг. Разработчик или девопс в декларативном стиле определяет что какая инфраструктура ему нужна.
- Pay as you go - плата только реально потребленные ресурсы. Место в S3, реально потребленные cpu и mem в функциях, контейнерах и БД.
Вполне исчерпывающее определение того, что такое serverless.
Тонкая грань отделяющая serverless от других сервисов в облаках
Определение выше проводит довольно четкую границу отделяя serverless от остального мира. Но эта граница не четкая так как облачные провайдеры предоставляют сервисы такие как Managed Kubernetes. Этот сервис можно притянуть к определениям выше:
- Kubernetes кластер может масштабироваться в записимость от нагрузки на него.
- Заботу о инфраструктуре и масштабировании берет на себя провайдер
- При изменении емкости кластера мы платим только за реально потребляемые ресурсы.
Но за ресурсы мы платим с неким запасам, плюс костоянная плата за control plane кластера.
Провайдеры не относят этот сервис к serverless и считаю, что это верно. Но тут я хотел только показать, что грань отделяющая serverless довольно размытая. Также еще есть PaaS %)
Принципы построения serverless
Пару слов о том какими принципами нужно/можно/стоит руководствоватьс�я при работе с serverless:
- Микросервисность
- Ориентация на события в системе. [Event-driven architecture](https://microservices.io/patterns/data/event-driven-architecture.html
- Слабая связанность и высокая атомарность выполняемых задач.
Как итог - гибкая и легко масштабируемой архитектура по умолчанию.
Когда стоит применять
Если нагрузка вашего сервиса хорошо прогнозируема, постоянна и интенсивна, и запросы к нему равномерно распределены в течение всего оцениваемого периода — serverless может оказаться более дорогим решением чем зарезервированные ресурсы Kubernetes кластера например.
Что дает serverless
Позволяет разработчикам сфокусироваться на коде, а не разворачивать, настраивать и обслуживать какую‑л�ибо инфраструктуру (серверы, виртуальные машины, контейнеры).
Часто даёт возможность снизить операционные расходы по сравнению с запуском приложений на виртуальной машине или в средах контейнерной виртуализации — за счёт более эффективного распределения мощностей провайдером.
Минимизирует риски непредсказуемости спроса в случае как переоценки, так и недооценки будущей нагрузки. А значит, вам проще принимать решения о добавлении в приложение новых возможностей или о запуске рекламной кампании.
from: Всё, что вы хотели знать о бессерверных технологиях, но боялись спросить
В моем вольном пересказе:
- Экономия при не полной утилизации ресурсов. Есть порог выше которого будет экономия
- Экономия при при сильно разном профиле нагрузки в течении суток/месяца
- Если разработка - это узкое место, то уменьшает time to market
- Не нужны компетенции и время на поддержку инфраструктуры
- Хорошая масштабируемость на непредсказуемой нагрузке
Обзор строительных блоков serverless
Сервисы и примеры этой статьи приведены на основе AWS, Yandex Cloud и совсем немного Azure.
Все serverless инструменты можно разделить на следующие категории:
- Вычисления
- Хранение бинарных и структурированных данных
- Интеграции и процессы
По ссылкам ниже можно найти описание сервисов предлагаемых облачными провайдерами:
Далее рассмотрим сервисы подробнее
Вычисления
Сервисы для выполнения вычислений появились первыми и на данный момент хорошо развиты и имеют очень схожие контракты в разных облачных провайдерах.
Два лсновных типа сервисов - это о�блачные функции и бессерверные контейнеры.
Облачные функции
В Yandex Cloud так выглядит интерфейс создания/редактирования облачных фунеций:
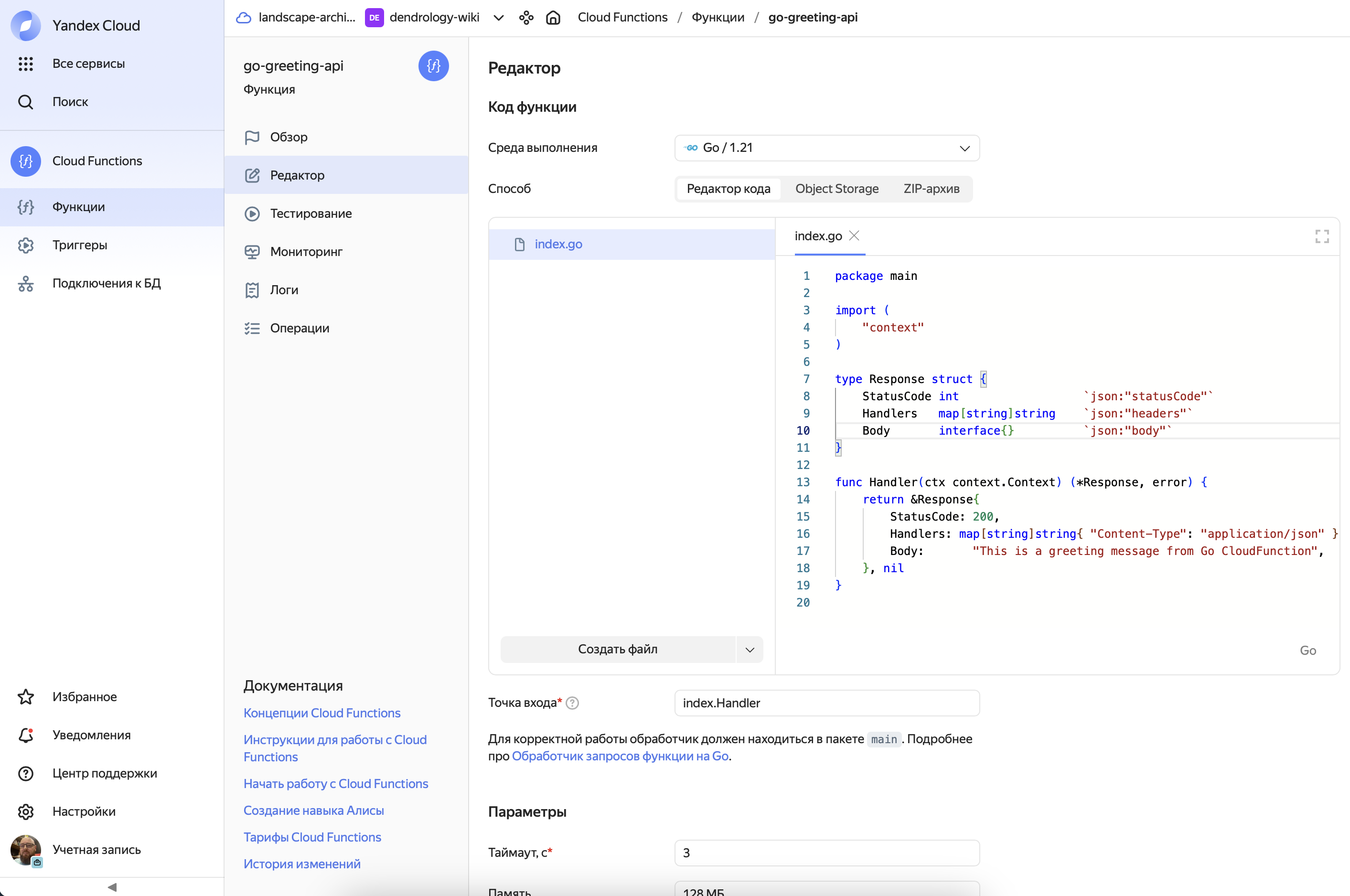
Функции на скриптовых языках будут переданны в рантайм как есть, а для компилируемых будет выполнена компиляция при создании/сохранении. Также допускается добавление зависимостей.
Важно! Не смотря на то, что в функции можно пис�ать много кода и добавлять зависимости, не стоит злоупотредлять этим. Большие функции будут долго запускаться, увеличивать таймауты и цену каждого выполнения.
Взаимодействие с облачными функциями очень похоже у разных провайдеров - это https. Но провайдер берет на себя обработку транспорта и в функцию передается уже подготовленный контекст вызова. Здесь разработчику не нужно заботиться о web фреймворках.
AWS Lambda
runs your code in response to events without requiring provisioning or management of servers
It automatically scales compute resources and you pay only for the compute time used
The main benefits are no server management, automatic scaling, pay-per-use billing, and performance optimization options.
Основные возможности предоставляемые AWS Lambda:
- Возможно использовать кастомный контейнер в качестве рантайма
- Поддерживаемые языка: Java, Node.js, Python, R, .NET, Go, Rust, C++ и дригуе с кастомными рантаймами
- Архитектуры: x86_64 и arm64
- Возможность подключить VPС, сеть для доступа к приватным ресурсам
Пример функции из AWS:
export const handler = async (event, context) => {
//console.log('Received event:', JSON.stringify(event, null, 2));
console.log('value1 =', event.key1);
console.log('value2 =', event.key2);
console.log('value3 =', event.key3);
return event.key1; // Echo back the first key value
// throw new Error('Something went wrong');
};
Yandex Cloud Functions
Основные возможности предоставляемые Yandex Cloud Functions:
- Поддерживаемые языка: Java, Node.js, Python, R, .NET, Go, PHP, Bash, Kotlin
- Архитектуры: x86_64
- Возможность подключить VPС, сеть для доступа к приватным ресурсам
Пример функции из Yandex Cloud:
module.exports.handler = async function (event, context) {
return {
statusCode: 200,
body: 'Hello World!',
};
};
Метрики из коробки
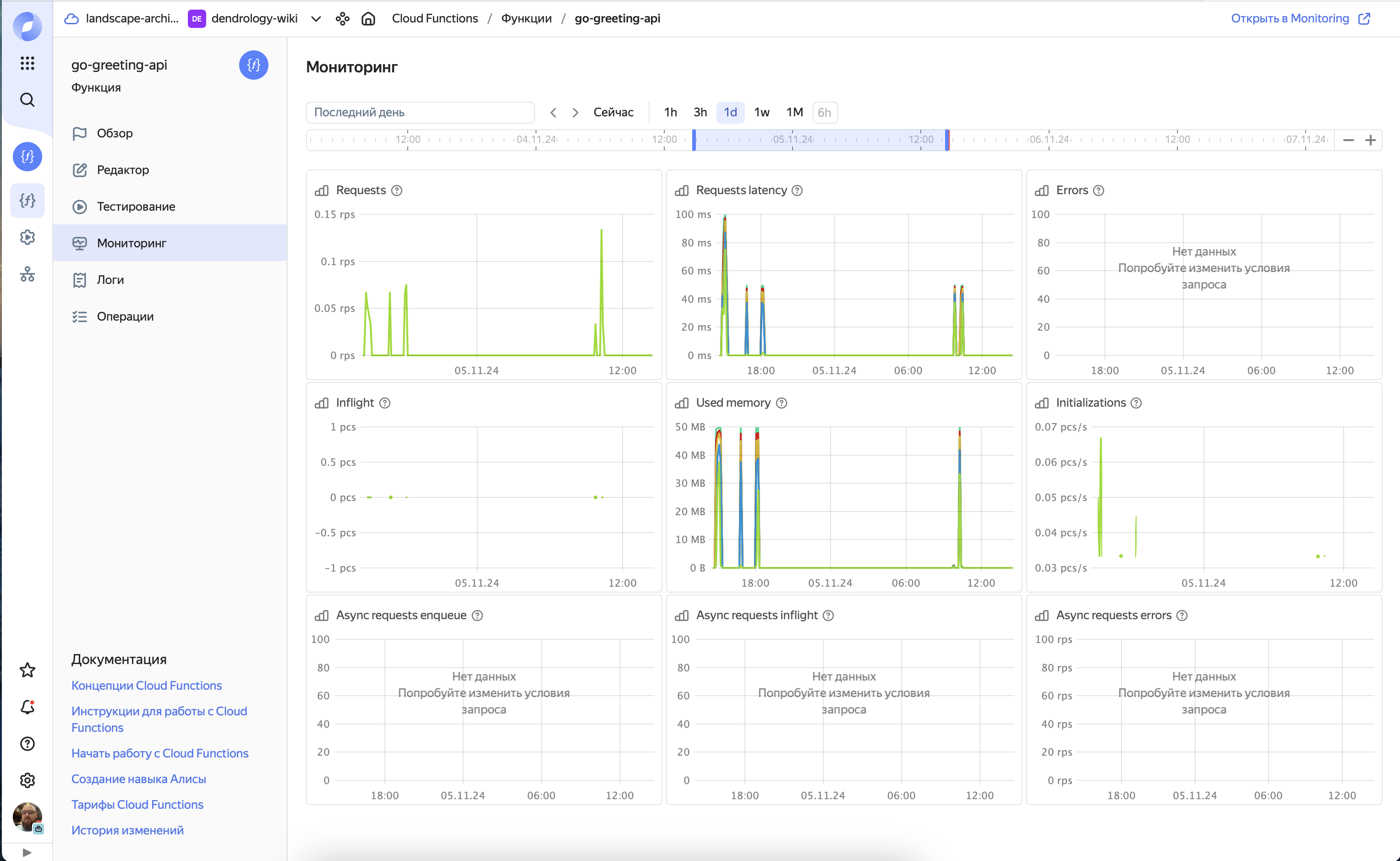
В логих по умолчаню считается время выполнения и потребленные ресурсы
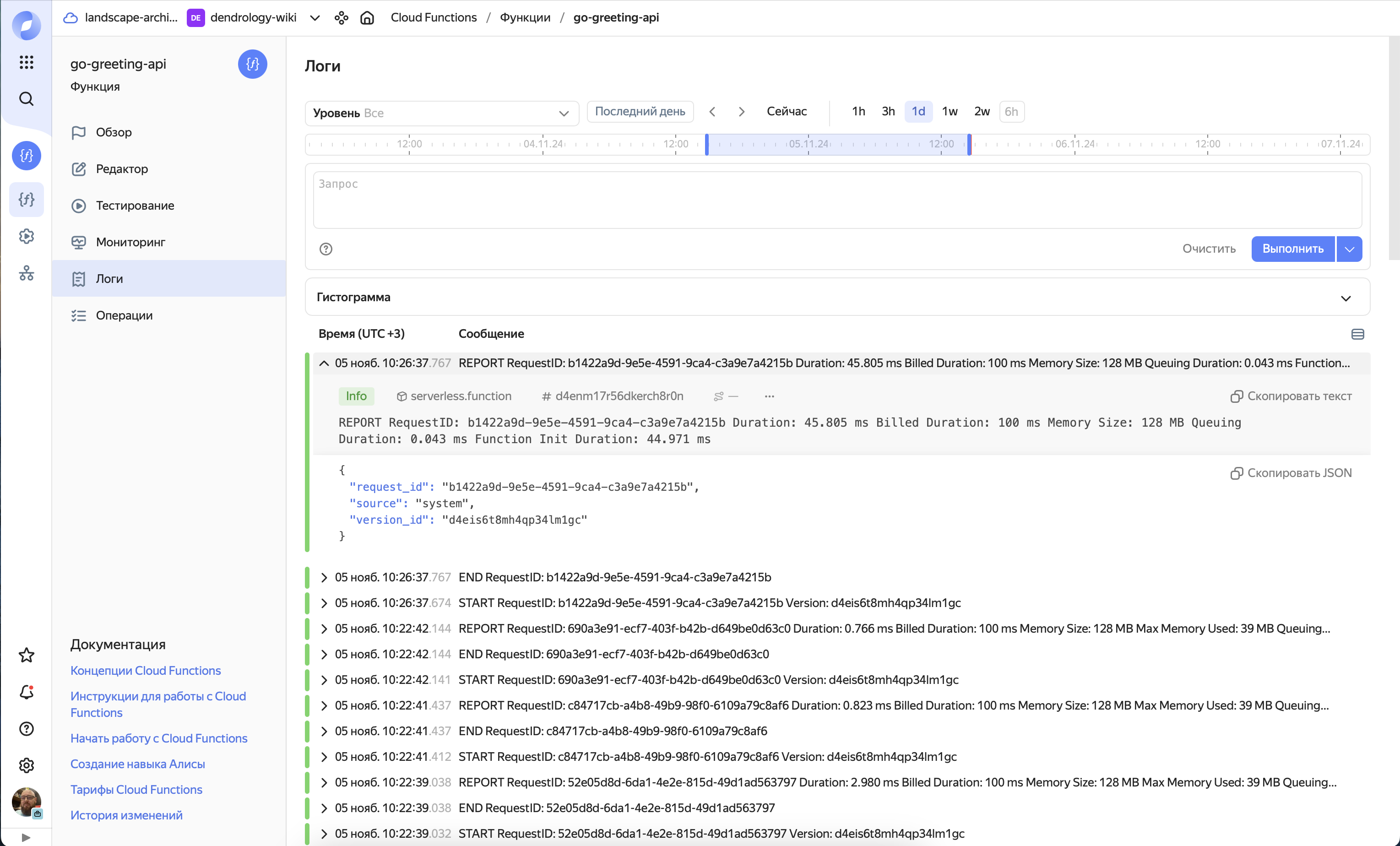
REPORT RequestID: b1422a9d-9e5e-4591-9ca4-c3a9e7a4215b
Duration: 45.805 ms
Billed Duration: 100 ms
Memory Size: 128 MB
Queuing Duration: 0.043 ms Function Init Duration: 44.971 ms
Бессерверные контейнеры
Бессерверные контейнеры - это почти как Kubernetes кластер. Отличие в том, что для контейнера нужно описать только требуемые ресурсы, политики доступа, указать VPC (облачную суть), таймауты и далее не нужно заботиться где и как будет развернут конейнер. Влатить нужно только за реально отработанное время, время простоя при отсутствии запросов не нужно оплачивать.
Провайдеры предоставляют следующие сервисы:
Взаимодействие с контейнерами отличается от облачных функций. Тут провайдер обеспечивает только доставку http запроса в контейнер. Контейнер должен содержать в себе Tomcat для Java или Echo для Go, чтобы иметь возможность принять и обработать http запрос.
Amazon Elastic Container Service + AWS Fargate
Сервис умеет:
- Запускать контейнеры и брать деньги болько за реально потребленные ресурсы :)
- Предоставлять доступ к приватным ресурсам через VPC и private links для доступа к сервисам облака
- Stop инстансы. Дешевле но без гарантий непрерывной работы.
- Масштабирование из коробки
Yandex Serverless Containers
Сервис умеет:
- Запускать контейнеры и брать деньги болько за реально потребленные ресурсы :)
- Предоставлять доступ к приватным ресурсам через VPC
- Масштабирование из коробки
Пример сервиса (https://gitverse.ru/seed/plant-name-parser-service), который можно запустить в Yandex Serverless Containers. Это cloud-ready сервис и он ничем не отличается от любого другого контейнера для дназначенного для запуска в Kubernetes.
cloud-ready - это приложение в контейнере с возможностью конфигурировать его через переменные окружения. Как результат обеспечивается неизменность самого контейнера и возможность запустить его с любой среде.
Аналогично облачным функциям для контейнеров есть и метрики
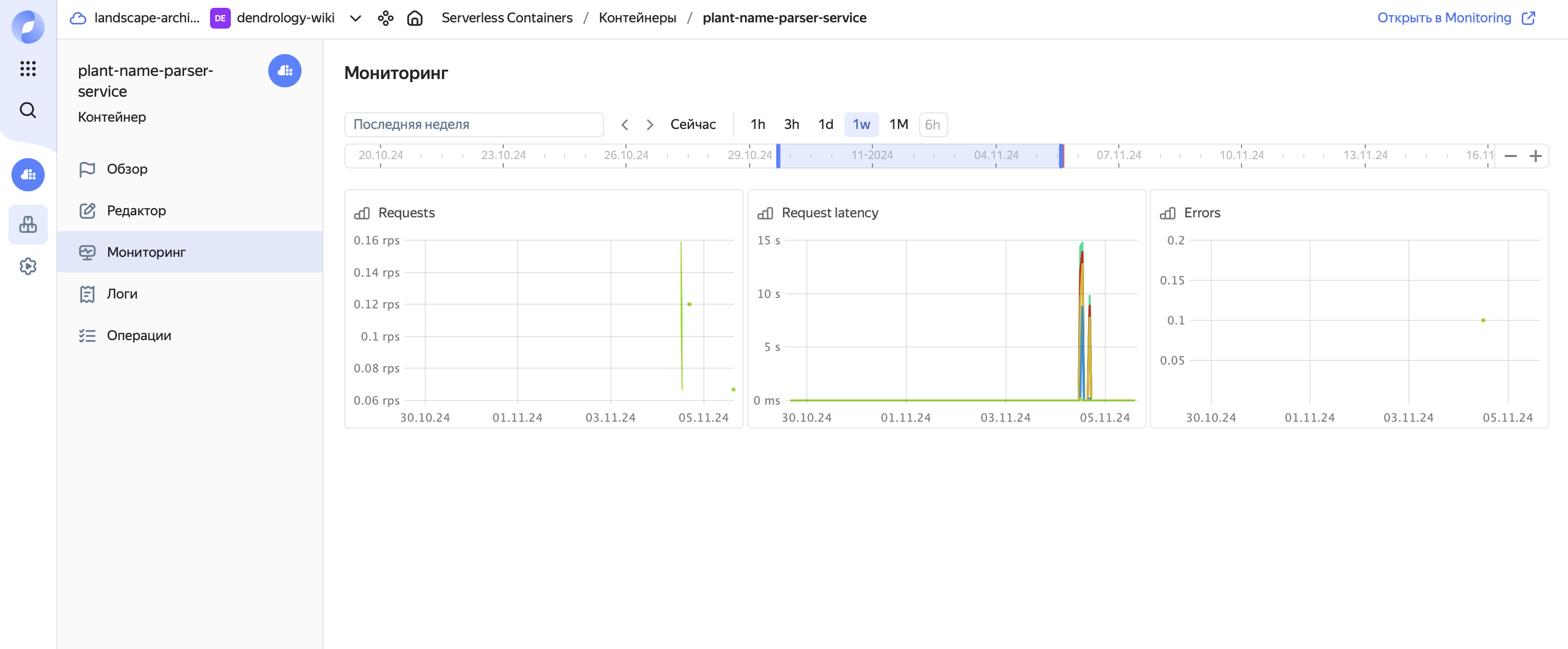 и логи
и логи
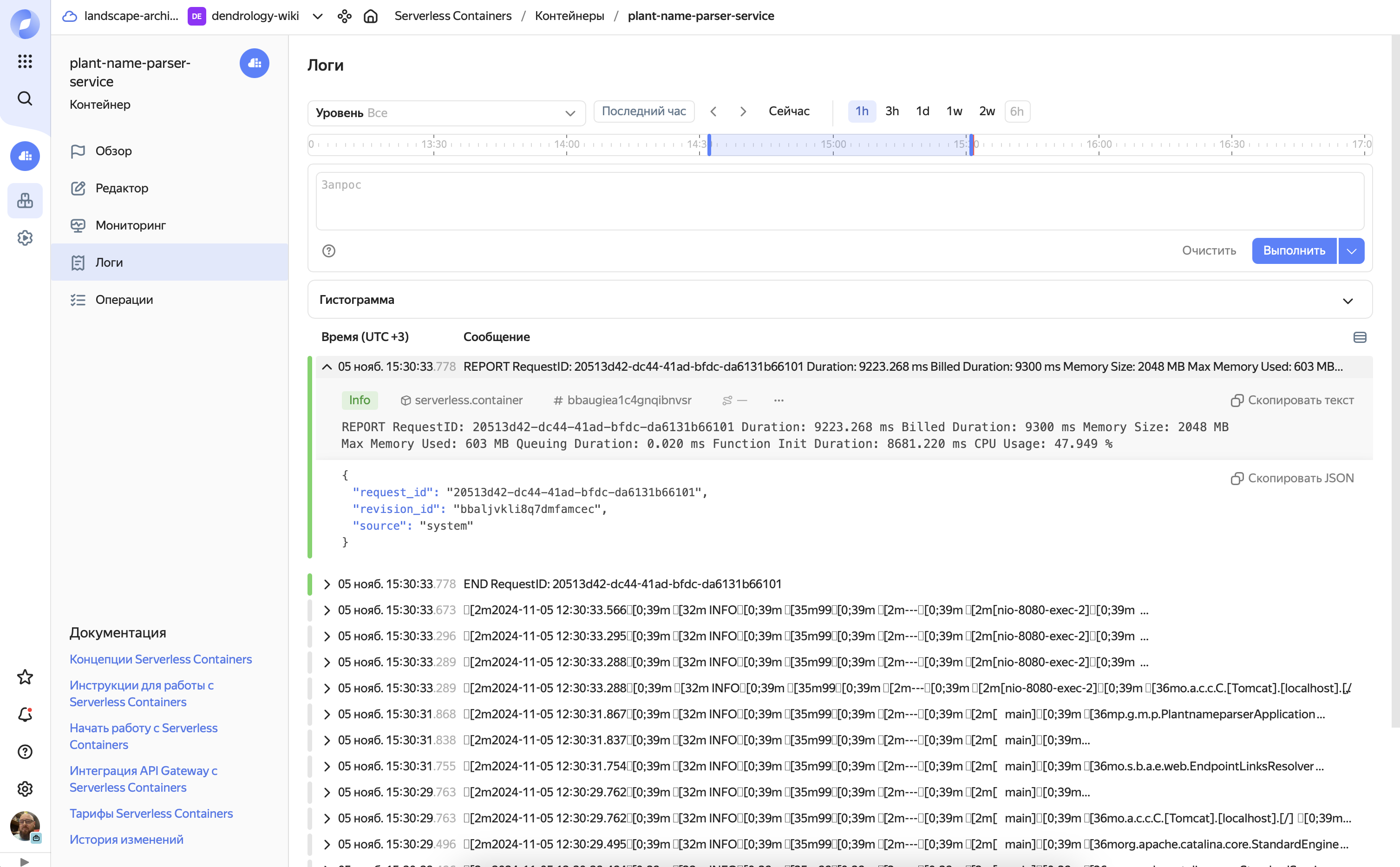
Первый запуск для тежелого Java сервиса по парсингу названий растений. Время запуска очень большое так как это Java + Spring Boot и совсем не оптимизированный контейнер в ~270MB [1cpu(20%)/2048MB]
REPORT RequestID: 20513d42-dc44-41ad-bfdc-da6131b66101
Duration: 9223.268 ms
Billed Duration: 9300 ms
Memory Size: 2048 MB
Max Memory Used: 603 MB
Queuing Duration: 0.020 ms
Function Init Duration: 8681.220 ms
CPU Usage: 47.949 %
Первый запуск для простого сервиса на Go в контейнере размером в 7.35MB [1cpu(100%)/128MB]
REPORT RequestID: 48feb0d8-3d43-4835-83ad-34e2167cb6a7
Duration: 96.994 ms
Billed Duration: 100 ms
Memory Size: 128 MB
Max Memory Used: 42 MB
Queuing Duration: 0.038 ms
Function Init Duration: 95.126 ms
CPU Usage: 15.625 %
Хранение бинарных и структурированных данных
Object storage
Начнем с объектного хранилища.
Объектное хранилище предназначено для хранения бинарных файлов, а также может выступать простым хранилищем для JSON, Yaml и других форматов.
Интерфейсы у сервисов S3 и Object Storage совместимы. Для взаимодействия с Yandex Object Storage в документации предлагается использовать AWS CLI
Также, с помощью сторонних к сервису инструментов проводить анализ структурированных данных (json, yaml). Доступные инструменты: Yandex Query, Amazon Athena, Trino.
Сервис позволяет:
- Хранить файлы как объекты
- Предоставлять к файлам публичный доступ (SPA UI, static data)
- Управлять жизненным циклом, организовать уровни хранения информации в зависимости (время доступа)/(цена за операцию)
- Генерировать события при изменениях данных и обработывать их в Lambda (AWS)
- Выполнять трансформацию при записи или чтении ланных. Выполняется через дополнительную функцию Lambda (AWS)
- Использовать версионирование данных в бакете
Пример создания bucket и загрузки данных в него:
#!/usr/bin/env python
#-*- coding: utf-8 -*-
import boto3
session = boto3.session.Session()
s3 = session.client(
service_name='s3',
endpoint_url='https://storage.yandexcloud.net'
)
s3.create_bucket(Bucket='bucket-name')
s3.upload_file('this_script.py', 'bucket-name', 'py_script.py')
Мониторинг из коробки:
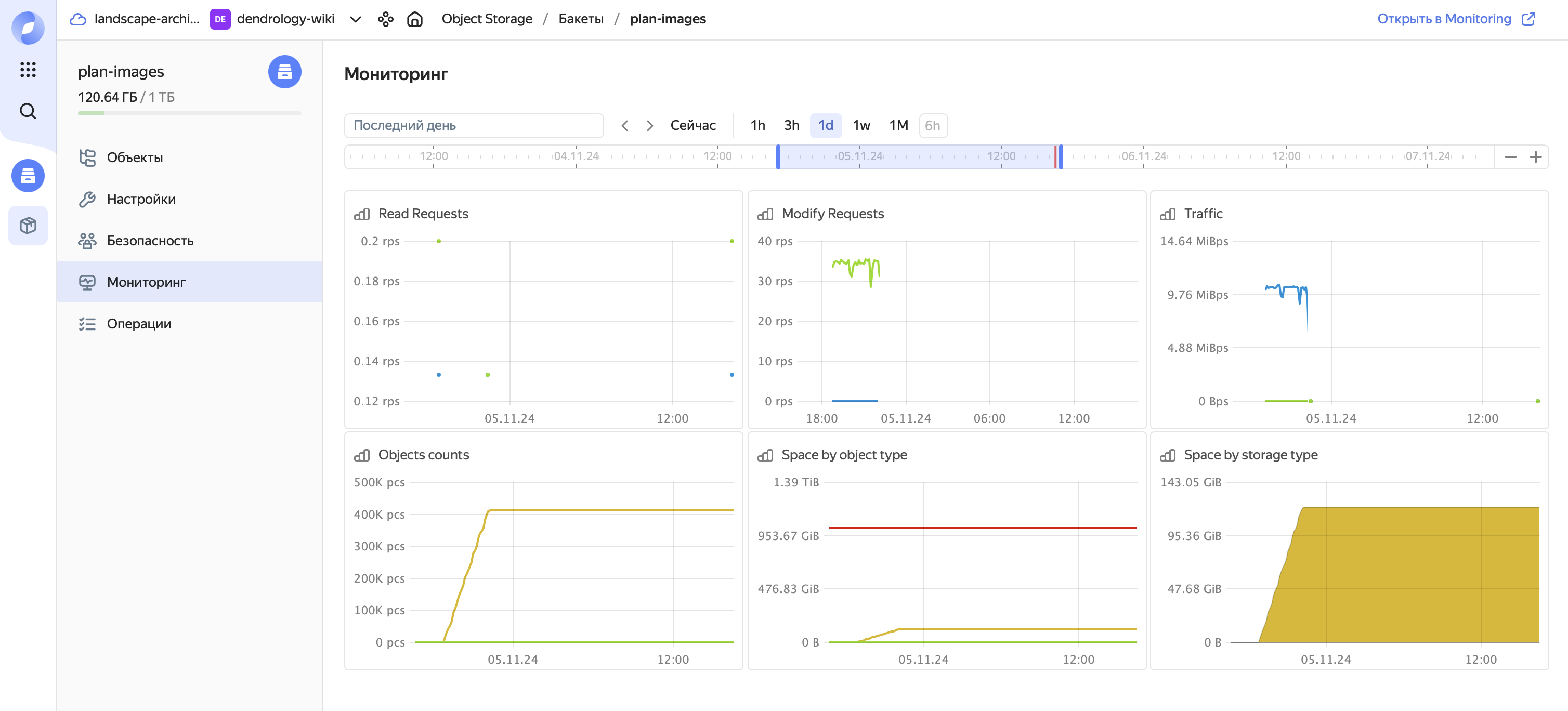
Key-value, SQL, Graph databases
AWS имеет большой набор serverless баз данных:
- Amazon DynamoDB - Serverless, NoSQL, fully managed database with single-digit millisecond performance at any scale
- Amazon Aurora Serverless - Amazon Aurora Serverless is an on-demand, autoscaling configuration for Amazon Aurora. Amazon Aurora provides unparalleled high-performance and availability at global scale with full MySQL and PostgreSQL compatibility.
- Amazon Neptune Serverless - Amazon Neptune Serverless allows you to run and instantly scale graph workloads, without the need to manage and optimize database capacity. With Neptune Serverless, you can create a graph database for your workload using the three most popular graph query languages: Apache TinkerPop Gremlin, openCypher, and SPARQL. Neptune Serverless automatically determines and provisions the compute and memory resources to run the graph database and scales capacity up and down based on the workload’s changing requirements to maintain consistent performance.
- Amazon OpenSearch Serverless - Amazon OpenSearch Serverless is a serverless option in Amazon OpenSearch Service. As a developer, you can use OpenSearch Serverless to run petabyte-scale workloads without configuring, managing, and scaling OpenSearch clusters. You get the same interactive millisecond response times as OpenSearch Service with the simplicity of a serverless environment.
У Yandex Cloud все намного проще. У них есть YDB ;), которая с одной стороны реализует Distributed SQL и контракт DynamoDB, а с другой стороны имеет serverless режим. В результате мы имеем аналоги Amazon DynamoDB и Amazon Aurora Serverless.
Интеграции и процессы
В AWS доступны сервисы:
- Amazon Simple Queue Service - Fully managed message queuing for microservices, distributed systems, and serverless applications
- AWS Step Functions - Visual workflows for distributed applications
- Amazon API Gateway - Amazon API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale.
Аналоги сервисов в Yandex Cloud:
- Yandex Message Queue - Сервис очередей для обмена сообщениями между компонентами распределённых приложений и микросервисов.
- Yandex Workflows - Автоматизация рабочих процессов с помощью визуального конструктора
- Yandex EventRouter - Обмен событиями между сервисами и сервисами Yandex Cloud с возможностью их фильтрации, трансформации и маршрутизации.
- Yandex API Gateway - Управляемые API с помощью спецификации OpenAPI 3.0
Arch.docs. Диаграммы и как это рисовать
Отдельной архитектурной документации для serverless нет и используются диаграммы для облака.
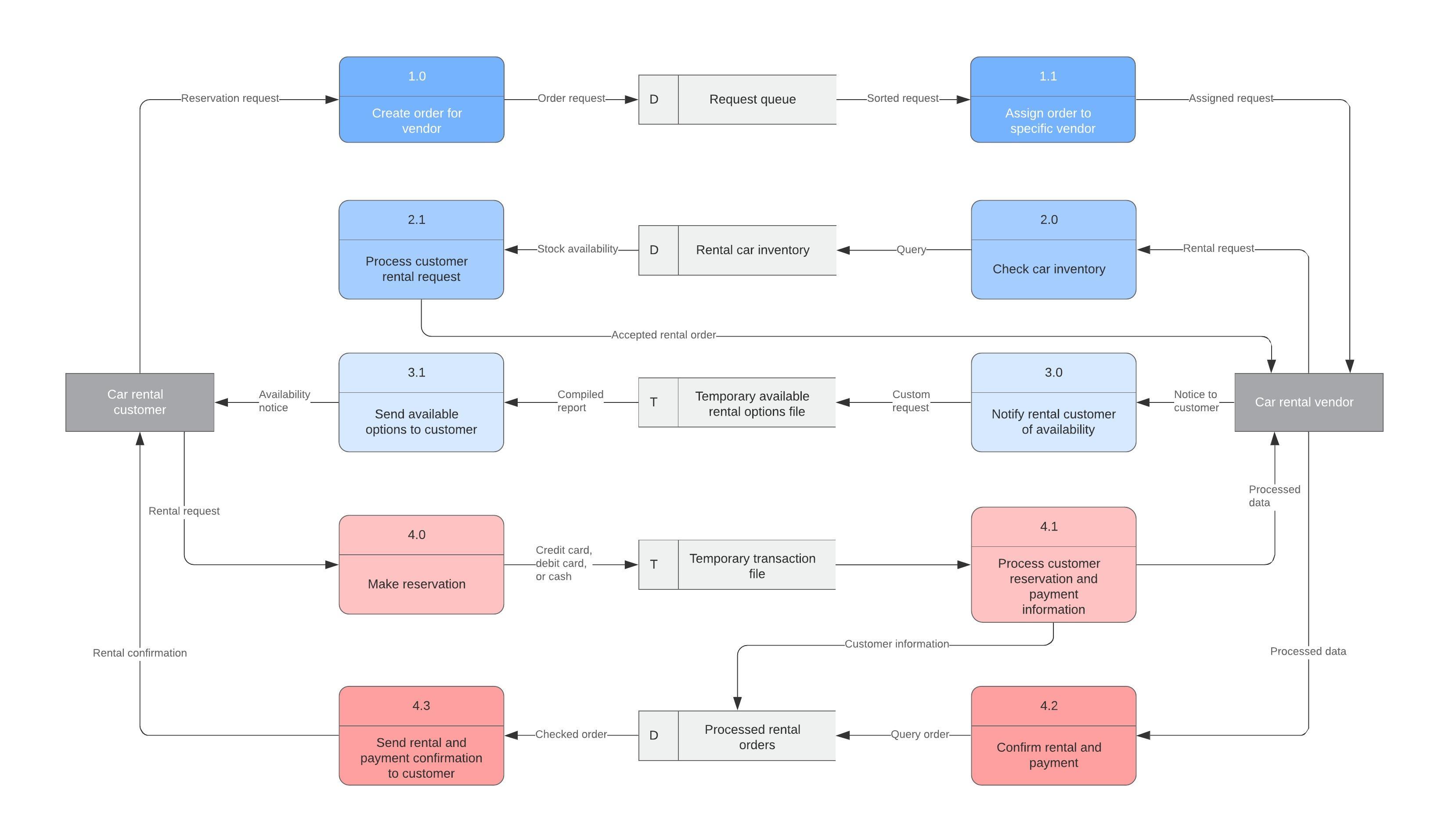
Для составления архитектурной документации используют схемы подобныей этой:
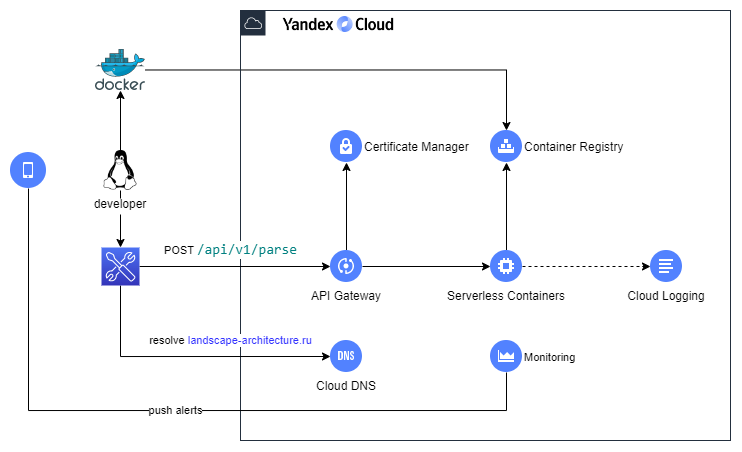
На диаграмме показываются сервисы и интеграции между ними. Так как в serverless стоит придерживатся микросервисной и eda архитектур, то сервисы вычисления на данной диаграмма должны выражать отдельные функции. По одной функции на сервис.
Sequence Diagram
Для долонения онформацией о поведении системы используют сиквенс диаграммы, иногда bpmn.
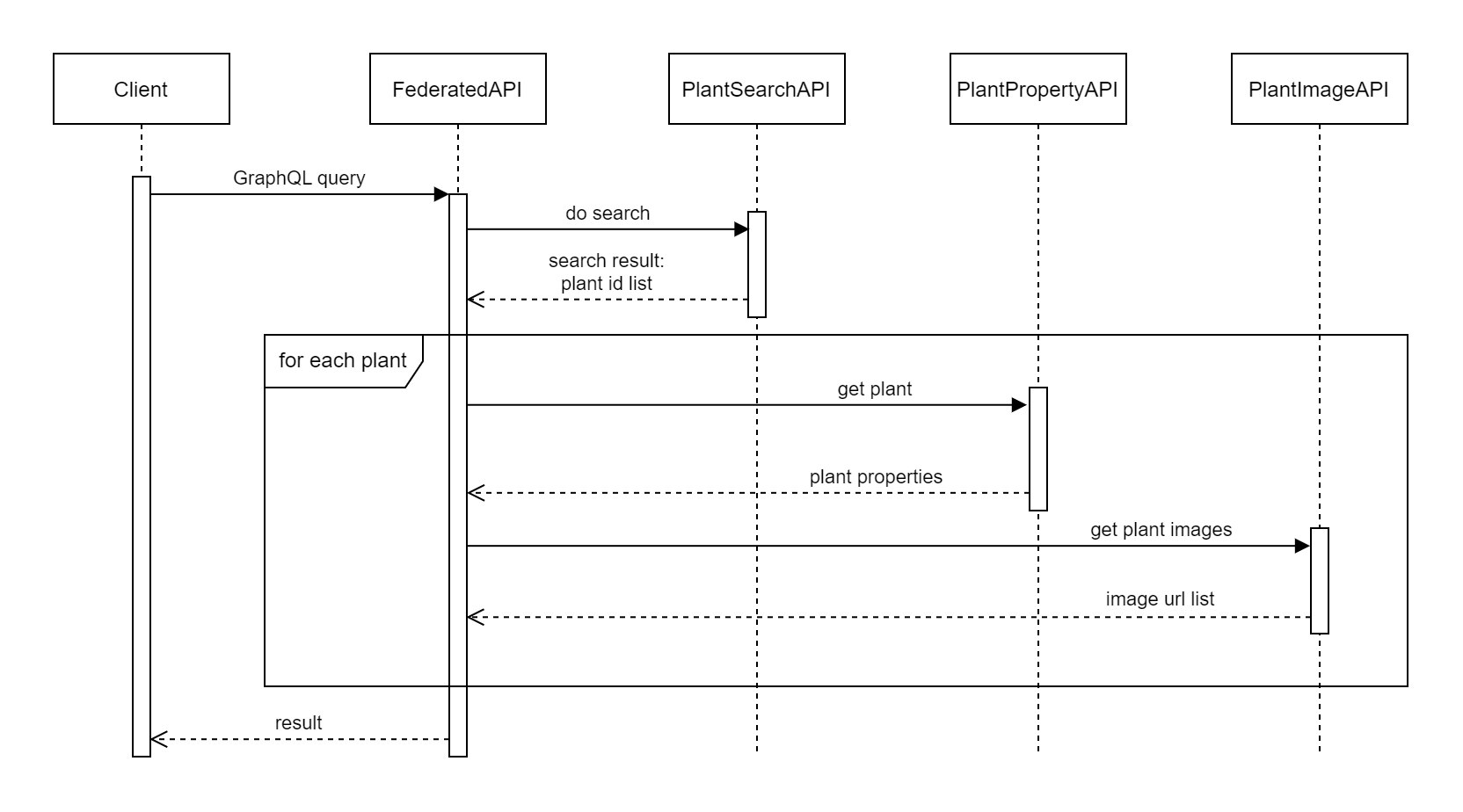
Data Flow Diagram Часто дополняются Data Flow Diagram, DFD, особенно для систем которые занимаются обработкой данных.
Deployment Diagram
Так как облачная инфраструкт�ура и сервисы могут быть созданы и создаются из кода, то предпочтительный путь - это создавать сразу описание инфраструктуры, которое в последствии можно визуализировать.
Инфраструктура обычно описывается и управляется с помощью инструмента Terraform. Далее пример описания bucket в Terraform:
# main.tf
resource "aws_s3_bucket" "my_bucket" {
bucket = "my-unique-bucket-name"
tags = {
Name = "MyS3Bucket"
Environment = "Production"
}
}
Примеры
Greeting serverless function with Bash
Рассмотрим пример простой функции на Bash ;) в Yandex Cloud
echo '{
"statusCode": 200,
"headers": {"Content-Type":"application/json"},
"body": "Hello from bash ;) !"
}'
Пример вызова функции с таймингами:
### results from idea http client
GET https://dendrology.wiki/api/try/bash-greeting
# Response code: 200 (OK); Time: 560ms (560 ms); Content length: 20 bytes (20 B)
# Response code: 200 (OK); Time: 237ms (237 ms); Content length: 20 bytes (20 B)
# Response code: 200 (OK); Time: 831ms (831 ms); Content length: 20 bytes (20 B)
# Response code: 200 (OK); Time: 109ms (109 ms); Content length: 20 bytes (20 B)
# Response code: 200 (OK); Time: 834ms (834 ms); Content length: 20 bytes (20 B)
Greeting serverless function with Go
Функция на Go, которая возвращает приветствие выглядит так:
package main
import (
"context"
)
type Response struct {
StatusCode int `json:"statusCode"`
Handlers map[string]string `json:"headers"`
Body interface{} `json:"body"`
}
func Handler(ctx context.Context) (*Response, error) {
return &Response{
StatusCode: 200,
Handlers: map[string]string{ "Content-Type": "application/json" },
Body: "This is a greeting message from Go CloudFunction",
}, nil
}
Тестирование и тайминги:
### results from idea http client
GET https://dendrology.wiki/api/try/greeting
# Response code: 200 (OK); Time: 1022ms (1 s 22 ms); Content length: 48 bytes (48 B)
# Response code: 200 (OK); Time: 811ms (811 ms); Content length: 48 bytes (48 B)
# Response code: 200 (OK); Time: 191ms (191 ms); Content length: 48 bytes (48 B)
# Response code: 200 (OK); Time: 101ms (101 ms); Content length: 48 bytes (48 B)
# Response code: 200 (OK); Time: 136ms (136 ms); Content length: 48 bytes (48 B)
# Response code: 200 (OK); Time: 138ms (138 ms); Content length: 48 bytes (48 B)
# Response code: 200 (OK); Time: 194ms (194 ms); Content length: 48 bytes (48 B)
И еще одна функция на Go
package main
import (
"fmt"
"io"
"net/http"
"strconv"
)
func Handler(rw http.ResponseWriter, req *http.Request) {
rawX1 := req.URL.Query().Get("x1")
rawX2 := req.URL.Query().Get("x2")
x1, err := strconv.Atoi(rawX1)
if err != nil {
rw.WriteHeader(501)
return
}
x2, err := strconv.Atoi(rawX2)
if err != nil {
rw.WriteHeader(501)
return
}
rw.WriteHeader(200)
rw.Header().Set("Content-Type", "application/json")
io.WriteString(rw, fmt.Sprintf("{\"result\": %v}", x1 + x2))
}
// ### Call Go math
// GET https://dendrology.wiki/api/try/math/plus
// ?x1=7
// &x2=13
UI with Bash cloud function :)
Данная функция читает index.html в файловой системы, заменяет в нем "DATE" на текущею дату и возвращает результат клиенту. Браузер получает html и рендерит его.
DATA=$( cat index.html )
CUR_DATE=`date`
DATA=$(echo $DATA | sed "s/DATE/$CUR_DATE/")
DATA=$( echo $DATA | base64 )
echo '{"statusCode": 200, "headers": {"Content-Type":"text/html"}, "isBase64Encoded": true}' | jq ". += {\"body\": \"$DATA\"}"
Пример вызова функции с таймингами:
### results from idea http client
GET https://dendrology.wiki/api/try/bash-ui
# Response code: 200 (OK); Time: 550ms (550 ms); Content length: 1002 bytes (1 kB)
# Response code: 200 (OK); Time: 168ms (168 ms); Content length: 1002 bytes (1 kB)
# Response code: 200 (OK); Time: 641ms (641 ms); Content length: 1002 bytes (1 kB)
# Response code: 200 (OK); Time: 296ms (296 ms); Content length: 1002 bytes (1 kB)
Try to open https://dendrology.wiki/api/try/bash-ui in your browser.
Пример содержит загрузку данных по onload из двух источников
- https://dendrology.wiki/api/try/greeting - cloud function in go
- https://dendrology.wiki/api/try/bash-greeting - cloud function in bash и действие по кнопке, которое складывает два числа обращаясь к go cloud function here https://dendrology.wiki/api/try/math/plus?x1=2&x2=3

Serverless контейнер. Java, Spring Boot, ANTLR
Простой сервис, который принимает строку парсит ее и возвращает результат. Ничего не хранит, stateless.
- https://gitverse.ru/full-stack.blog/plant-name-parser-service
- https://hub.docker.com/repository/docker/aganyushkin/plant-name-parser-service/general
- https://full-stack.blog/blog/17_plant_name_parser_service
### Parse plant name in plant-name-parser service
POST https://dendrology.wiki/api/v1/parse
Content-Type: application/json
{
"text": "betula pendula"
}
# Response code: 200 (OK); Time: 11890ms (11 s 890 ms); Content length: 136 bytes (136 B)
# Response code: 200 (OK); Time: 11395ms (11 s 395 ms); Content length: 136 bytes (136 B)
# ...
# Response code: 200 (OK); Time: 168ms (168 ms); Content length: 136 bytes (136 B)
# Response code: 200 (OK); Time: 267ms (267 ms); Content length: 136 bytes (136 B)
# Response code: 200 (OK); Time: 108ms (108 ms); Content length: 136 bytes (136 B)
# Response code: 200 (OK); Time: 212ms (212 ms); Content length: 136 bytes (136 B)
# Response code: 200 (OK); Time: 207ms (207 ms); Content length: 136 bytes (136 B)
Result:
{
"genus": {
"text": "betula"
},
"species": {
"text": "pendula"
},
"subspecies": null,
"alternative": null,
"variety": null,
"cultivar": null,
"form": null
}
Serverless контейнер. UI in Go container
В контейнере реализован веб сервер, который рендерит UI. Из браузера загружаются данные по onload из cloud function. Ручка поиска реализована в томже контейнере.
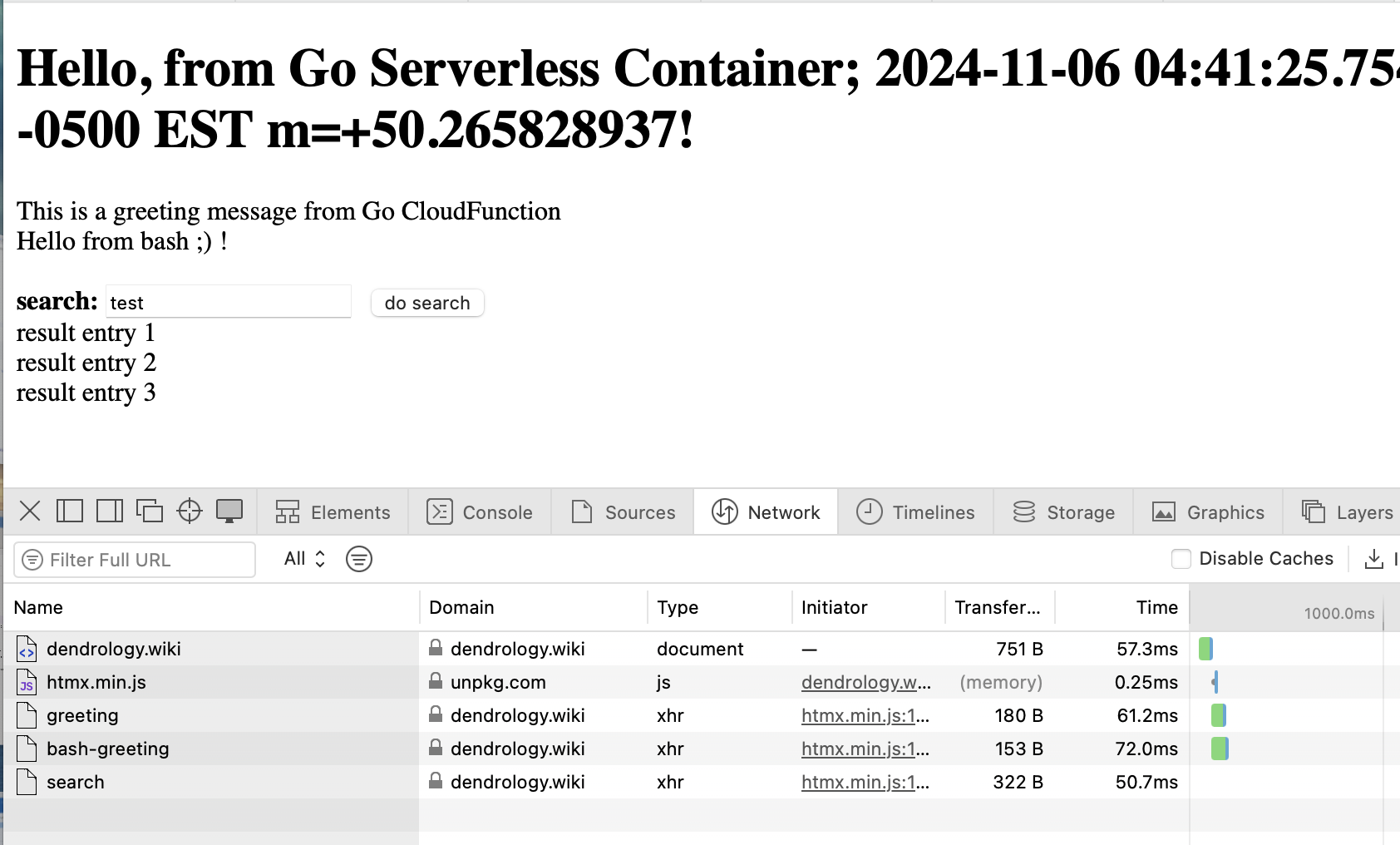
### Call Go container with web UI
GET https://dendrology.wiki/
# Response code: 200 (OK); Time: 901ms (901 ms); Content length: 1047 bytes (1.05 kB)
# Response code: 200 (OK); Time: 632ms (632 ms); Content length: 1047 bytes (1.05 kB)
# Response code: 200 (OK); Time: 287ms (287 ms); Content length: 1048 bytes (1.05 kB)
# Response code: 200 (OK); Time: 122ms (122 ms); Content length: 1048 bytes (1.05 kB)
# Response code: 200 (OK); Time: 669ms (669 ms); Content length: 1048 bytes (1.05 kB)
# Response code: 200 (OK); Time: 107ms (107 ms); Content length: 1048 bytes (1.05 kB)
Static content hosting. SPA, Personal blog, etc...
Далее рассмотрим вариант serverless хостинга для блога. По аналогии производится размещение SPA.
Основная часть тут - это S3 или Object Storage сервис на котором хранятся файлы js, html, css etc...
Объектное хранилище настраивается так, чтобы к был файлам публичный доступ.
При больших нагорузках можно задействовать CDN (Amazon CloudFront, Yandex Cloud CDN).
Используется сервис Yandex Cloud DNS для управления зоной.
Используется сервис Yandex Certificate Manager для получения и регулярного обновления TLS сертификата от LetsEncrypt.
Так выглядит бакет с содержимым текущего блога:
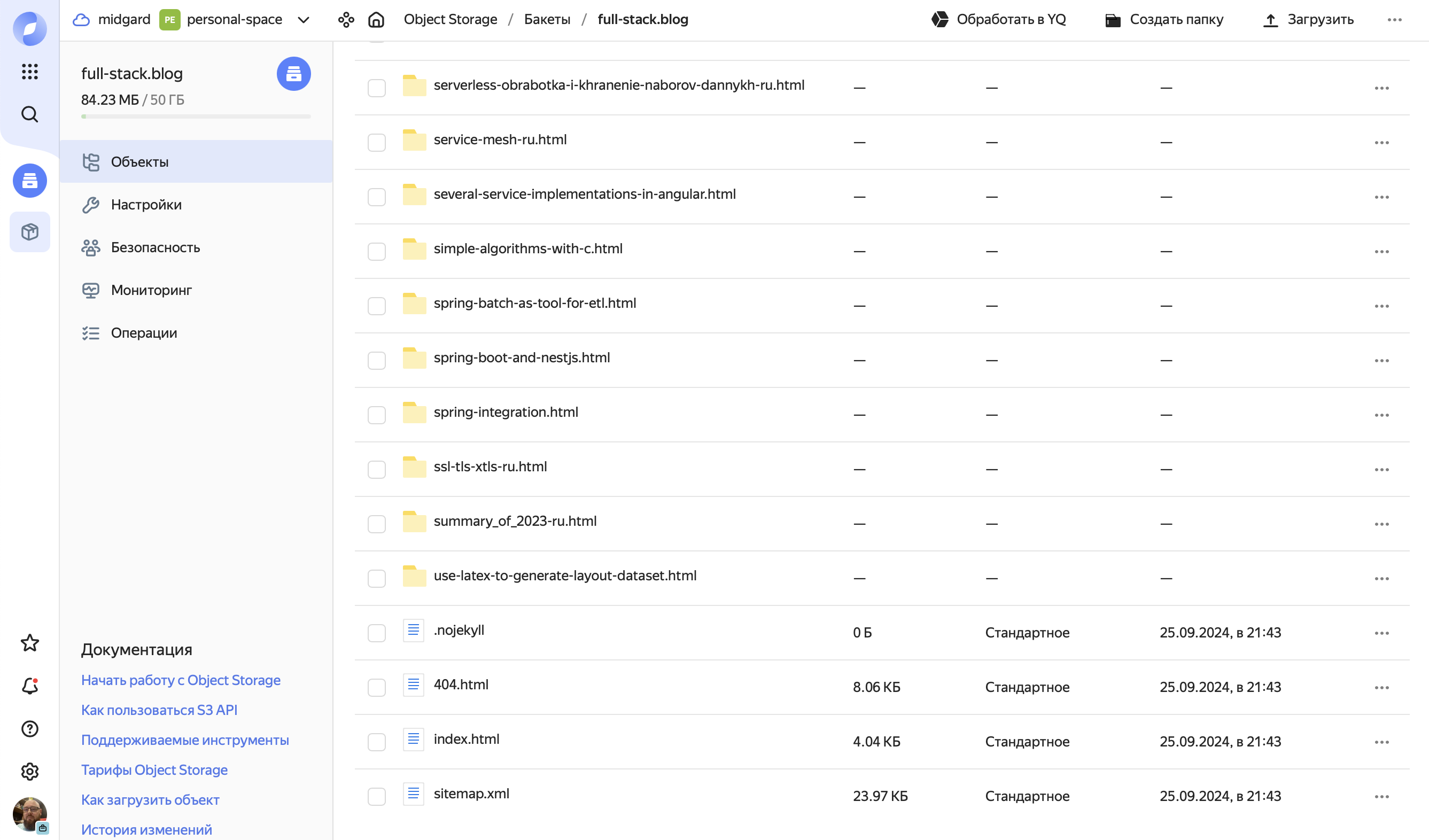
Аналогично в облаке размещаются SPA. Вместо VM + Nginx используется S3.
Бывают случаи когда Nginx для SPA выполнял дополнительную логику по роутингу, переписывание путей и подобное. В таком случае в облаке потребуется сделать дополнительные обработчики а формате AWS Lambda либо в API Gateway, либо в Cloud Front, либо как трансформация при чтении объекта из бакета.
Цена решения по месяцам:
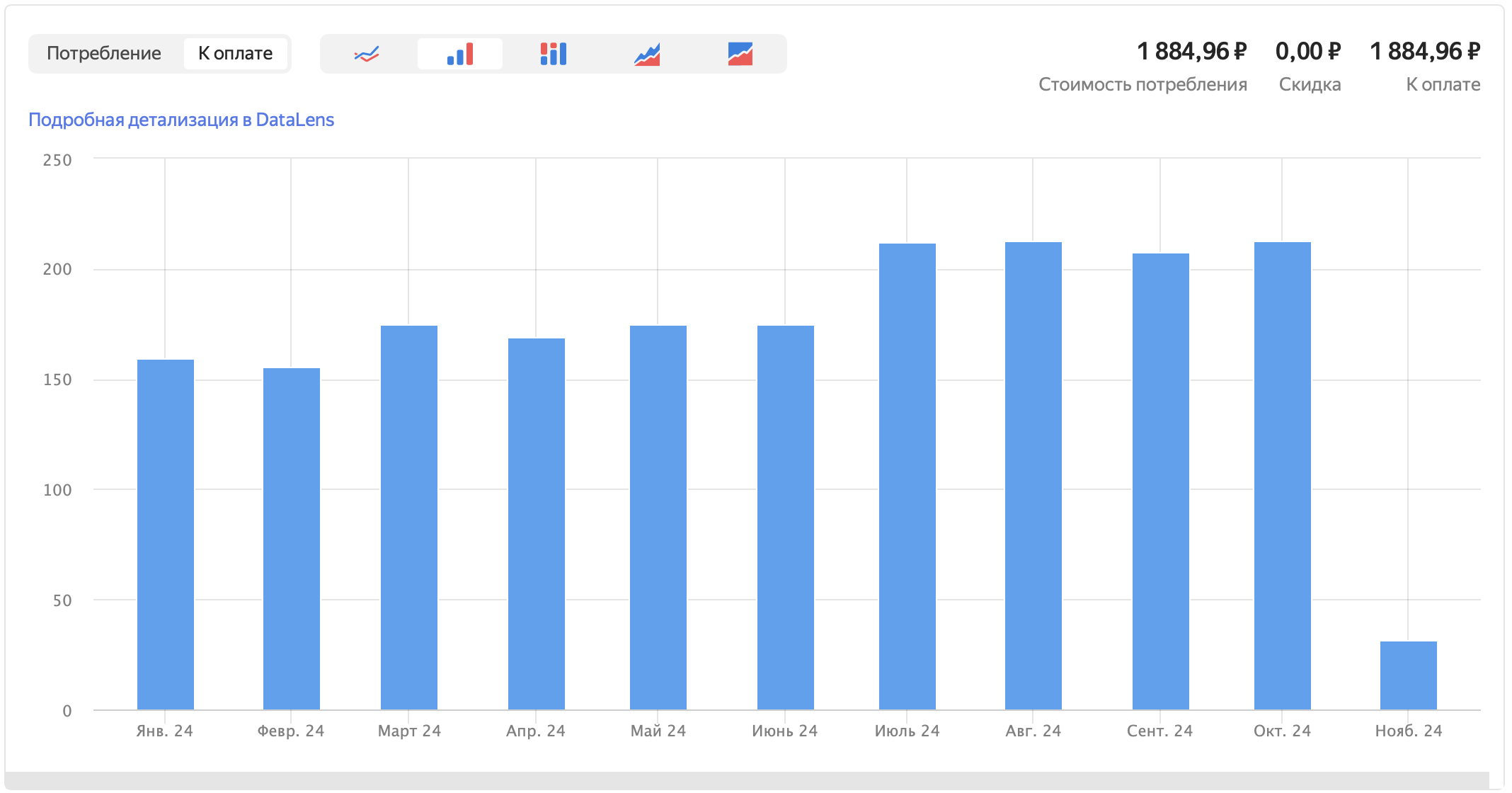
При минимальной стоимости VM == 1 238,80 ₽ в месяц в том же облаке (да, новерное можно и дешевле хостинг поискать).
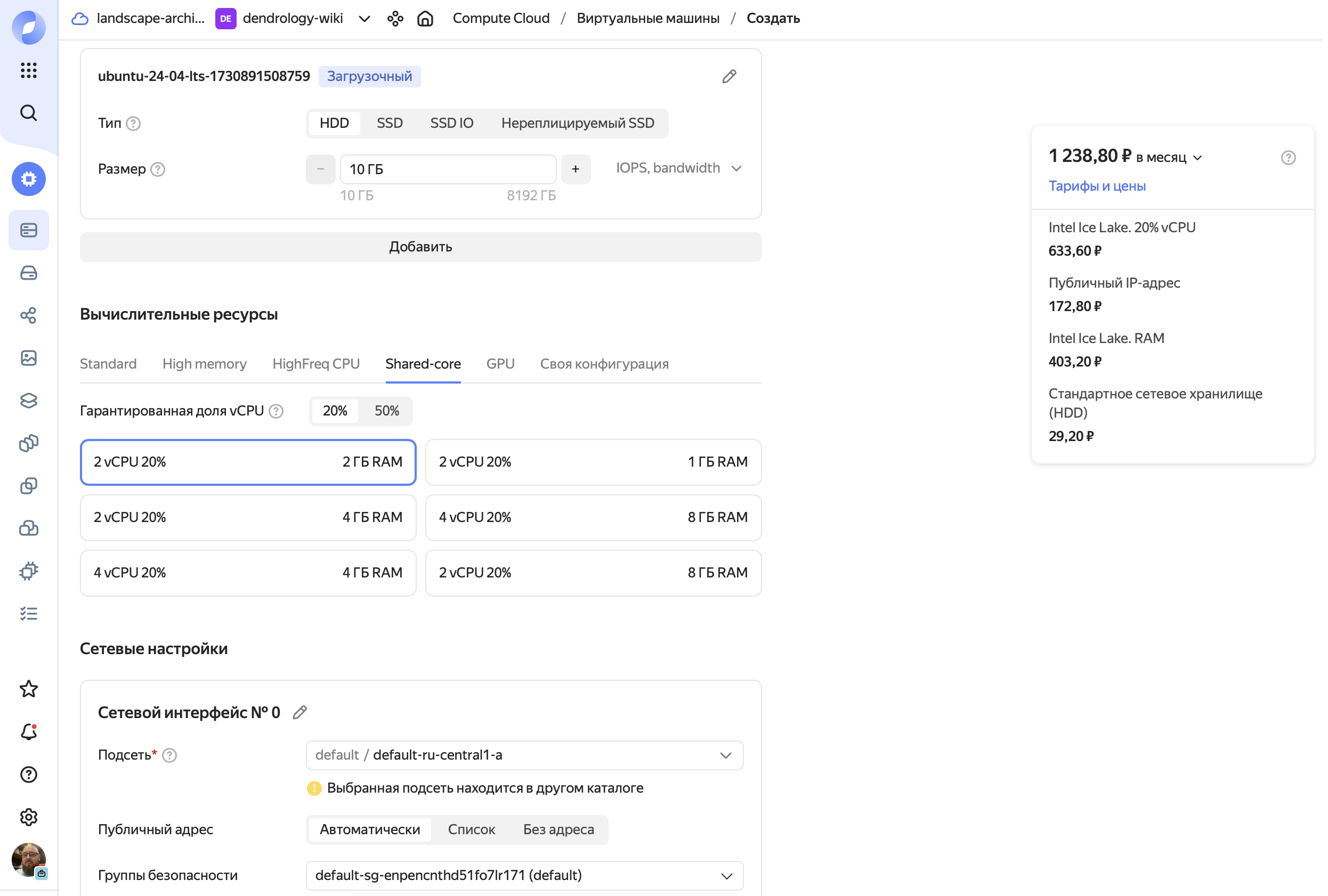
Весь DevOps/поддержка такого решения сводится к созданию бакета через UI и выполнению команды для загрузки новой версии:
BUCKET_NAME=secret_bucket_name
BUILD_DIR=./build/
S3_API_ENDPOINT=--endpoint-url=https://storage.yandexcloud.net/
aws s3 cp --recursive $BUILD_DIR s3://$BUCKET_NAME/ $S3_API_ENDPOINT
Serverless обработка и хранение наборов данных
В статье Serverless обработка и хранение наборов данных описано решение.
Event-driven architecture (EDA) и serverless
Хорошее описание применения EDA и serverless на yandex scale 2024.
Основные сервисы Yandex Cloud для EDA организующие очереди/потоки данных:
- Yandex Message Queue - очередь сообщений
- Yandex Data Streams - поток сообщений
В качестве входного шлюза может быть использован Yandex API Gateway, который принимает события и отправляет их в очередь.
Сепвисы для оркестрации и хореографии событий:
Для обработки событий:
- Yandex Cloud Functions и триггеры для интеграции с очередью
- Serverless Containers
vendor-lock. Облака, туда и обратно.
Не простая тема о том на сколько просто будет перестать платить облачному провайдеру и уйти в датацентр. Или начать платить другому облачному провайдеру.
Рассмотрим vendor-lock через сложность следующих вариантов миграции:
- Миграция с одного облачного провайдера на другой
- Миграция обратно в датацентр
Для того, чтобы хоть как-то формализовать наше приложение воспользуемся классификацией уровня адаптированности приложения к облаку.
- cloud ready - приложение в контейнере с конфигурировании через переменные окружения
- cloud friendly - удовлетворяет 12factor
- ...
- cloud native - описывает приложения, специально созданные и оптимизированные для полного использования преимуществ облачных вычислений
Миграция обратно в датацентр
Если кратко - обратного пути нет, а миграция из облака убивает serverless так как он возможен только в облаках.
Сложность миграции в DC нарастает от cloud ready до cloud native.
cloud ready - это приложение, которое может быть легко развернуто на любом K8s кластере и поэтому не затрудняет миграцию.
С ростом количества используемых сервисов повышается и сложность возврата в датацентр.
Для замены облачных сервисов существуют opensource проекты но они не всегда production ready, они требуют усилий на поддержку. Так например MinIO как замена Amazon S3 может вызвать большие проблемы при размещении большого поличества объектов по одному префиксу.
При движении в сторону cloud native неизбежно будут испоьзоваться все более и более заточенные на облако сервисы и отказаться от них или найти из замену будет все треднее и треднее. Хотя некоторые провайдеры идут на встречу и открывают свои наработки, так например YDB открыта и может быть развернута на собственной инфраструктуре.
Миграция с одного облачного провайдера на другой
Миграция между разными облачными провайдерами выполняется гораздно проще чем уход от облака. Причина этому то, что AWS был первым и очень быстро рос. Как результат не появилось конкурирующих стандартов например для S3, а существующие провайдеры являются догоняющими и вынуждены делать и набор сервисов похожий на AWS и контракты совместимые с ним.
Далее таблицы соответствияя сервисов различных облачных провайдеров:
- microsoft. AWS to Azure services comparison
- google. Compare AWS and Azure services to Google Cloud
- yandex. Сопоставление с Amazon Web Services
Так например Yandex Cloud использует aws cli для доступа к своим сервисам, предоставляет совместимость/аналоги сервисов таких как SQS, DynamoDB, Amazon Kinesis Data Streams, etc...
AuthN & AuthZ в serverless
В серверлесс важно иметь IdP как сервис, чтобы не поддерживать свой на VM :)
Аутентификация
В Yandex Cloud нет отдельного облачного сервиса, который бы предоставлял функции IdP. Но есть Yandex ID, Сбер ID и т.д.
В AWS есть специальный сервис для аутентификации пользователей приложенмя Amazon Cognito. Implement secure, frictionless customer identity and access management that scales.
В Azure есть отдельный сервис Azure AD B2C для путентификации пользователей.
Все эти сервисы предоставляют OIDC и позволяют аутентифицировать пользователей c authorization code flow и implicit flow.
Авторизация
Доступ к сервисам внутри облака организуется с помощью сервисных аккаунтов, которые позволяют одним сервисам вызывать другие и VPC. Это создает замкнутый контур в который нельзя попасть со стороны кроме как через API Gateway. API Gateway выполняет авторизацию входящих запросов.
Yandex API Gateway
Позволяет организовать авторизацию следующими методами:
- JWT, https://yandex.cloud/ru/docs/api-gateway/concepts/extensions/jwt-authorizer
- HTTP Basic, HTTP Bearer, API Key, https://yandex.cloud/ru/docs/api-gateway/concepts/extensions/function-authorizer
Amazon API Gateway
Позволяет организовать авторизацию следующими методами:
- JWT, https://docs.aws.amazon.com/apigateway/latest/developerguide/http-api-jwt-authorizer.html
- Lambda authorizers Use a Lambda authorizer (formerly known as a custom authorizer) to control access to your API. When a client makes a request your API's method, API Gateway calls your Lambda authorizer. The Lambda authorizer takes the caller's identity as the input and returns an IAM policy as the output.
- Client-side SSL certificates
- API keys
- авторизация по Amazon Cognito user pools
Заключение
Наверняка мой субъективный вывод, субъективные оценки и субъективные мысли никому не инетересны.
Позволю себе оставить тут свои впечатления от serverless:
Удобно, дешево, надежно.
- Автор
Ссылки. Посмотреть, почитать
- Создание приложен�ий с бессерверными архитектурами
- Serverless on AWS. Build and run applications without thinking about servers
- Всё, что вы хотели знать о бессерверных технологиях, но боялись спросить
- Yandex Scale 2024. Serverless
- Yandex Scale 2024. Serverless, youtube.com
- Yandex Scale 23
- The twelve-factor app
- Microservice Architecture
- Интересное о Serverless: хабрастатьи о применении, инструментах, кейсах и инструкциях для первого свидания
- Serverless Architectures on martinfowler.com
- Serverless-архитектура или бессерверные вычисления: обзор технологии
- Serverless in Yandex Cloud
- Соответствие стандартам и требованиям
- Облачные решения для финансов и страхования
- Yandex Cloud. Начало работы с Terraform
- EDA VISUALS, Small bite sized visuals about event-driven architectures