
Проблема
Подготовка данных для computer vision моделей иногда может занять очень много времени. Это проблема, так как замедляет процесс разработки, улучшения, адоптации моделей.
Оценка времени обработки одного пакета данных для решаемой нами задачи:
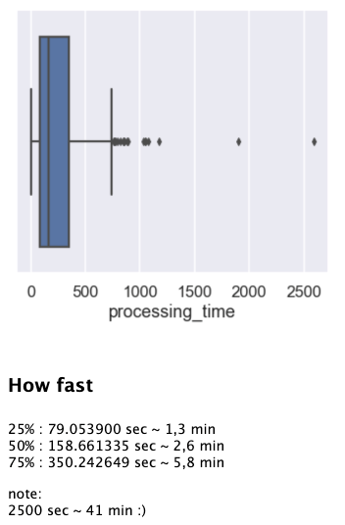
Обработка одного пакета с данными занимает много времени. Для тысяч пакетов время обработки будет слишком большим, что ограничит возможность добавлять или/и использовать данные для обучения.
Это сильно ограничивает нас в добавлении новых источников и изменении алгоритмов подготовки данных. Также, нужно как-то хранить данные, переиспользовать и предоставлять к ним доступ.
Решение
Сделаем полностью бессерверное решение в надежде сэкономить деньги и получить максимум гибкости. В основе решения будет AWS S3:
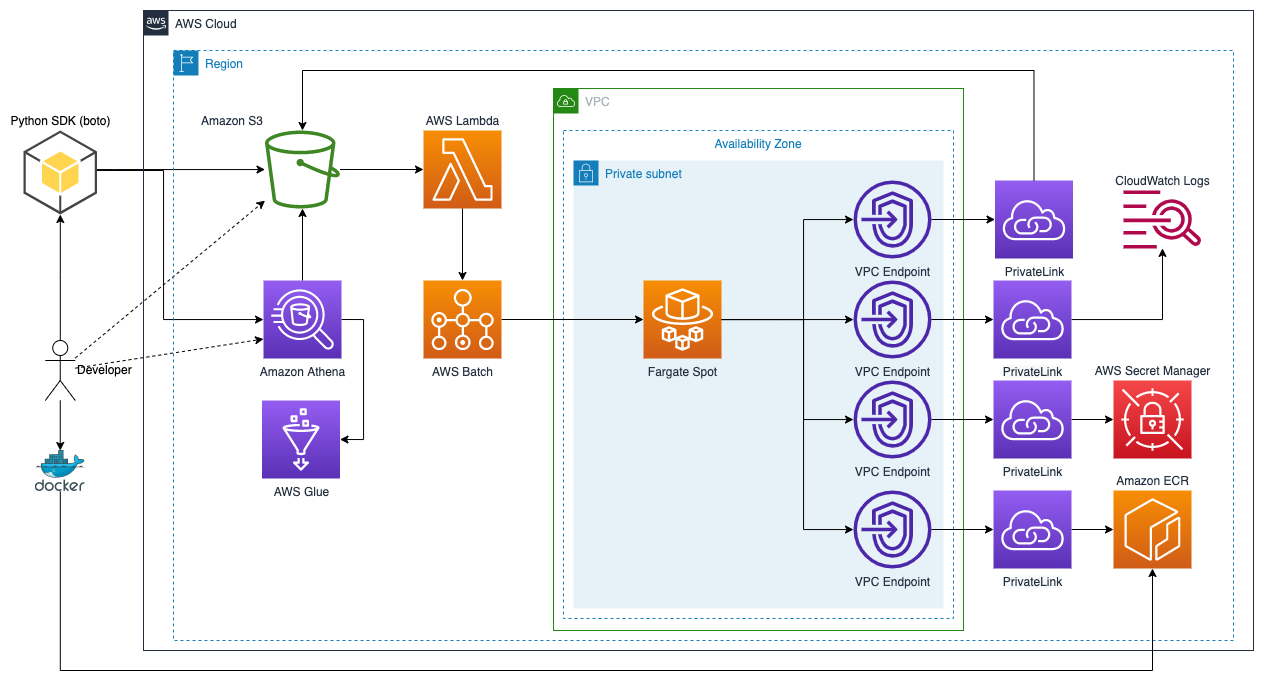
Идея достаточно проста - храним данные в S3, обрабатываем в AWS Batch на Fargate Stop инстансах. Это дает нам возможность платить за вычислительные ресурсы только тогда когда они нам нужны и к�огда нам нужно что-то обработать, использовать столько ресурсов сколько нужно.
S3 максимально снижает стоимость хранения данных. При необходимости, с помощью Amazon Athena можно выполнять SQL запросы к данным и формировать подвыборки данных, исследовать данные и т.п. Так как запросы к данным (SQL запросы. Скачиваие набора данных для обучения или какой-либо обработки не является SQL запросом.) - это достаточно редкая операция, поэтомы serverless сервис Amazon Athena нас вполне устраивает.
К тому же, мы можем использовать S3 Access Points для управление правами доступа к S3 для разных команд.
Компоненты:
-
S3 - хранилице для исходных данных, датасетов и метаданных датасетов. Разработчик с помощью python sdk может поучить список датасетов из S3, скачать метаданные и сам датасет.
-
AWS Lambda - триггер, который следит за новыми исходниками в S3 и запускает их трансформацию в элементы набора данных.
-
AWS Batch
<Fargate Spot>- пакетная обработка исходых данных. Эта связка обеспечивает минимальную стоимость при простоях и максимальную скорость обработки и масштабирования. AWS Batch берет на себя все задачи связанные с управлением задачами и вычислительными ресурсами. Нам нужно только создать несколько конфигураций. Прерывание инстансов в Fargate Spot не станет проблемой так как AWS Batch позаботится об управлении, а увеличение времени обработки не станет проблемой, так как подготовка датасета не влияет на пользователей. -
Amazon ECR - хранит образ задачи для подготовки данных.
-
Amazon Athena - предоставляет возможность выполнять SQL на данных в S3. Используется как инструмент создание подборок из полного надора данных. Позволяет отфильтровать только интересующие элементы, создать подборку и не дублировать данные в несколькох датасетах.
-
AWS Glue - требуется для "Amazon Athena" и хранит метаданные для него.
Пример триггера для AWS Lambda
Для решаемой задачи получится очень простая lambda функция:
import json
import boto3
batch = boto3.client('batch')
def lambda_handler(event, context):
errorMessage = None
for record in event["Records"]:
try:
s3 = record["s3"]
if s3["object"]["size"] > 0 and s3["object"]["key"].endswith('.zip'):
containerOverrides = {
'environment': [
{
'name': 'SOURCE_BUCKET',
'value': s3["bucket"]["name"]
},
{
'name': 'SOURCE_PATH',
'value': s3["object"]["key"]
},
],
}
parameters = {}
response = batch.submit_job(
jobQueue="name_of_processing_queue",
jobName="name_of_job",
jobDefinition="name_of_processing_definition",
containerOverrides=containerOverrides,
parameters=parameters)
except Exception as e:
print("ERROR")
print(e)
errorMessage = 'Error submitting Batch Job'
if errorMessage is not None:
raise Exception(errorMessage)
return {}
Получаем уведомление от S3 и создаем задачу для Batch. Бакет и исходный файл - это параметры и они передаются в обрабатывающий контейнер через переменные окружения, что также удобно при использовании контейнера локально.
Интеграция с PyTorch
В контексте этой задачи будет не плохо иметь сп�ециальный Dataset для PyTorch чтобы использование данных из общего хранилища было максимально простым.
Например использование готового датасета может выглядеть вот так:
set1_dataset = XXXDatasetForMaskRCNN(
dataset_key='subset_1_from_dataset_v1',
transforms=Compose([
ToTensor()
])
)
loader = DataLoader(
set1_dataset,
batch_size=1,
shuffle=True,
pin_memory=True,
drop_last=True
)
Работы с Athena тоже может быть включена в Python SDK для разработчиков
from xxx_dataset import XXX
xxx = XXX()
xxx.sql_query('SELECT * FROM "schema_name"."articles" LIMIT 7;')
xxx.freeze_dataset(
ds_key='subset_1_from_dataset_v1',
sql_query='''
SELECT * FROM "schema_name"."articles_rects"
WHERE "rect_type" = 'ABSTRACT'
;
'''
)
Заключение
Получилось сделать полностью serverless решение, которое предоставляет максимальную скорость подготовки данных при минимальных затратах. Постоянные траты - это хранение данных. За вычислительные ресурсы мы платим минимум и только за время работы наших задач.
Основная проблема также была решена. Время на подготовку или репроцессинг данных теперь не стремится в бусконечность.